Caches and data-oriented design (C++)
Cache is the most critical aspect of performance optimization
Although spacial locality is CS 101, it’s a powerful concept worth exploring further. This blog post covers two renowned CppCon 2014 talks: Mike Acton “Data-Oriented Design and C++” and Chandler Carruth: “Efficiency with Algorithms, Performance with Data Structures”. To summarize:
- Cache is the most critical aspect of performance optimization
- Compiler can only do so much if your code is not cache-friendly.
- Decision of using a struct of arrays vs. an array of structs should be informed by your data and its access patterns.
The common factor here is the cache. Both talks illustrate its importance with latency comparison numbers:
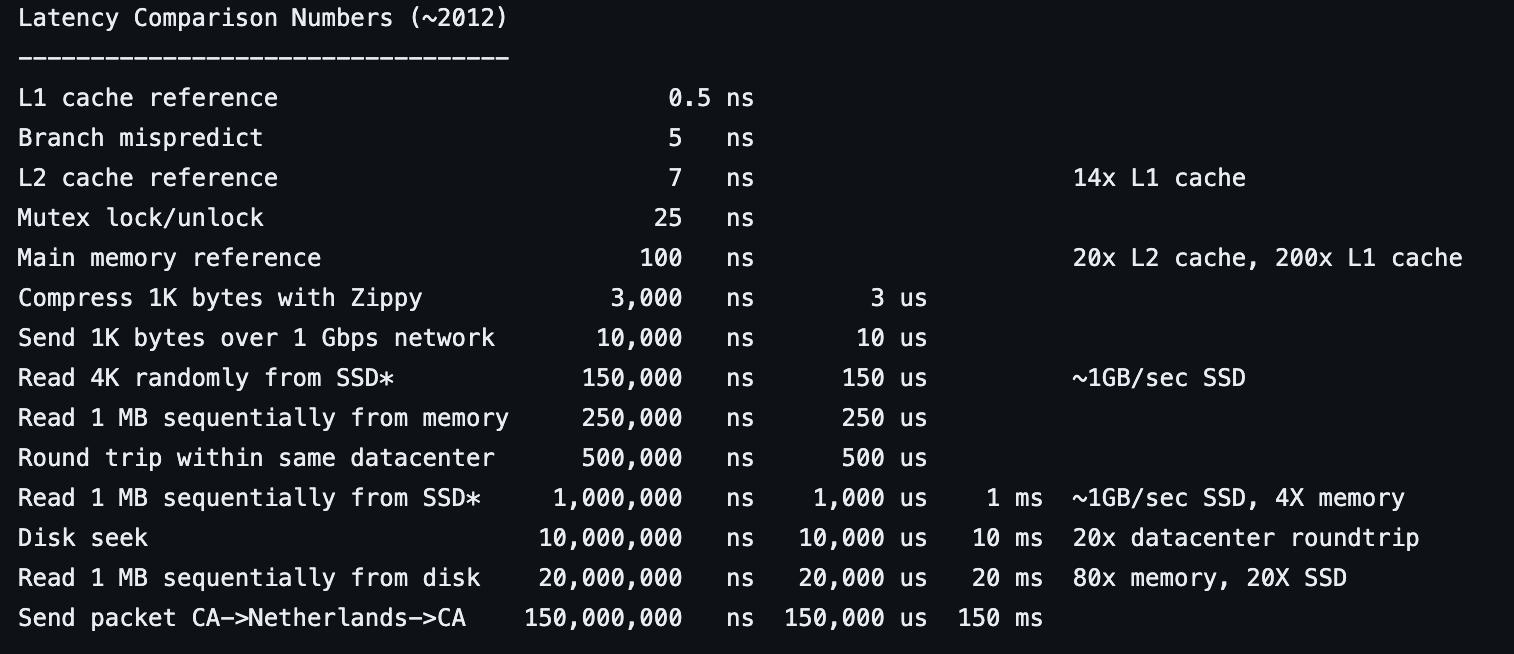
In other words, no mater how much the engineer or the compiler optimize the code, if memory access patterns are poor, the code will not perform well. Optimizing for better branch prediction is only worth so much when the main memory is being accessed continuously. Consequently:
- This influences your data structure choice, e.g. contiguous
std::vectorvs non-contiguousstd::list. - This influences the way you store/represent data, e.g. a struct of arrays vs. an array of structs.
These two points reflect the different emphasis of the two talks.
Data structure choice
Carruth argues that algorithm choice relates to efficiency, while data structure choice relates to performance. If performance is a concern, avoid using non-contiguous containers – chasing pointers inevitably leads to cache-unfriendly code. Instead of std::list, prefer std::vector. For example, when implementing a queue, opt for a ring buffer or a dynamic ring buffer rather than a linked list. Similarly, instead of std::map or std::unordered_map, prefer “dense” maps. In the event of hash collisions, the next data point access is likely free as it should live on the same cache line.
Data representation
Acton argues that OOP can lead to poor performance due to suboptimal representation of data. Consider a scenario where you have students with their respective details:
struct Student {
std::string name;
int age;
... // Bunch of properties
};
The OOP perspective assumes that a Student is self-contained and does not consider the presence of multiple students. Sometimes, this is a weakness. If you had a std::vector<Student> and iterated over it, accessing only a subset of its member variables:
std::vector<Student> students;
for (const auto& student : students) {
std::cout << student.name << std::endl;
}
this approach might be cache-unfriendly, especially if the Student struct had numerous member variables. You might end up wasting a significant portion of the cache line and not fully utilize data locality. In such a situation, a better approach might be:
std::vector<std::string> names;
std::vector<int> ages;
for (int i = 0; i < names.size(); ++i) {
std::cout << names[i] << std::endl;
}
While the above example is trivial, the idea itself can be a game changer in the real world.